
Pardon the lateness of this update, sickness and a hectic winter schedule kept this post in draft, but I hope you enjoy the BIGGER v2 Silicon in Irish benchmark!
The winner of the Silicon in Irish v2 benchmark isn’t Claude Opus 4.5. It isn’t GPT 5. It’s Google’s Gemini 3 Flash—a model that many have been sleeping on.
At 72.4% accuracy across an updated and expanded 1,341 Irish grammar tests, this model outperformed every flagship offering from Anthropic, OpenAI, and even Google’s own Gemini 3 Pro. Claude Opus 4.5 came in second at 70.3%—no surprise there, it’s an excellent model across most tasks. But the fact that a smaller, faster, cheaper model beat the most capable models on the market tells us something important: when it comes to Irish language competence, bigger doesn’t always mean better and that there is certain amount of consolidation in the baseline knowledge in these models (see Results below).
In this essay, I will be reporting on the updates in the benchmark in 2026, and discussing what I see happening next for the project.
If you are new to the series, here is a tl;dr:
- Part 1 — tested non-reasoning models on v1 (~73% ceiling)
- Part 2 — tested reasoning models on v1 (~78% with o1/o3)
- Part 3 — compared v1 findings with the Irish-BLiMP paper and Gaelcultúr test
Despite a year of model releases, despite models getting larger and more capable at other tasks, baseline Irish grammar competence has by and large plateaued—but that is only the baseline :]
What Changed: From Vibe Check to Rigorous Testing
In many respects, v1 of this benchmark was an exploratory vibe check. There weren’t any existing benchmarks and anecdotally everyone was saying the models were go dona (bad) 👎
Across the last number of months, I’ve been looking at ways to improve and hone in on the best parts of the benchmark, standardise the approach and broaden (and deepen) the scope of testing.
Bigger, Better and Structural Improvements
The benchmark now contains 1,341 tests up from 1131 across 25 grammatical features. We added over 200 new tests and two entirely new features:
- An Modh Foshuiteach (Subjunctive Mood)
- An Aimsir Gnáthchaite (Past Habitual Tense)
We also added edge case tests for difficult features like the clasal cóibhneasta (relative clause) with the copular form, ‘ is ’—one of the trickiest interactions in Irish grammar—or dealing with numbers inside of genitive case constructions.
Standardised Exercise Types
Every test now follows one of three standardised formats:
Type 1: Error Correction (Irish Only)
Mark the error with parentheses, model corrects it:
Níor (d'éist) sí leis an gceol ar chor ar bith.→ Níor éist sí leis an gceol ar chor ar bith.Type 2: Fill in the Blank
With or without hints:
Nach ___ tú ann ar chor ar bith? (bí)→ Nach raibh tú ann ar chor ar bith?Type 3: Constrained Translation
Irish hints reduce variation:
I gave (tabhair) her mother a gift (bronntanas).→ Thug mé bronntanas dá máthair.Reducing Translation Variation
This was crucial. In v1, open translation questions like “Translate: She called her friend”* allowed for more than one valid answer, making it hard to test specific grammatical features and even tougher to grade.
In v2, we constrain the output:
Chuir sí glaoch ___ cara. [She called her friend]→ ar a caraNow we’re testing whether the model knows that “ar a” for feminine possessive doesn’t trigger any initial mutations, not whether it can translate a sentence.
*Other translations include: Ghlaoigh sí a cara, Chuir sí glao ar a cara, Scairt sí ar a cara … etc.
Technical Setup
System Prompt
All models received the same system prompt:
You are taking an Irish grammar test. Follow these rules strictly:
OUTPUT FORMAT:- Respond with the answer on a single line at the end of any discussion- You MUST always provide an answer. Never leave the answer blank- If you are unsure, provide your best attempt
EXERCISE TYPES:1. Words in (parentheses) → correct the error, output full phrase2. ___ blanks → fill in the blank, output full phrase3. English language [hint] or Irish language (hints) → translate to IrishAgain it is important to note this is baseline testing: there are no feature-specific worked examples, no external references, no RAG, no retrieval from grammar databases. We’re testing what models know innately about Irish grammar.
All models were called using OpenRouter.
Challenges Encountered
Interestingly, larger models tended to overthink and produce persuasive-sounding reasoning that led to wrong answers. The system prompt’s insistence on “provide your best attempt” helped, but reasoning models especially would construct elaborate justifications for incorrect forms.
For example, here is Claude Opus 4.5’s thinking for ó thús (mí) an (Meitheamh):
I need to correct the grammatical errors in this phrase.
The phrase "ó thús" (from the beginning of) requires the genitive case for what follows.
1. **mí** → **mhí** (needs lenition after "thús")2. **an Meitheamh** → **na Meithimh** (genitive case)
ó thús mhí na MeithimhConfident.
Detailed to the point it made me double check.
Wrong. (Comment the correct answer 😉)
Additionally, models would sometimes return blank responses when token limits were too restrictive. We increased the limit from 500 to 5000, to no hard limit as issues arose. Sometimes models still refused to answer, and these were marked as incorrect. Reasoning effort is medium where applicable.
Model Results and Changes from V1 to V2
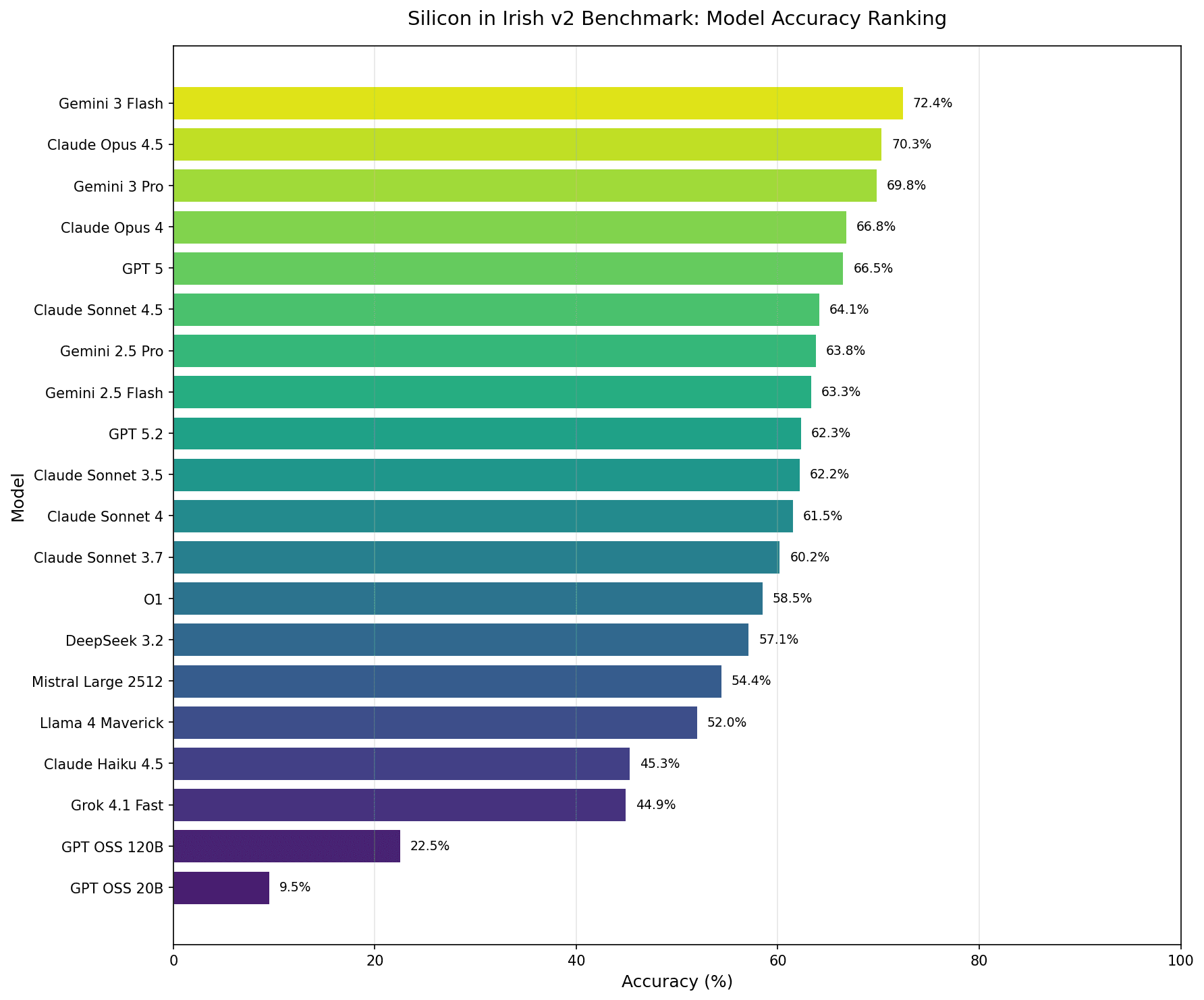
Flash beats Opus. Flash beats Pro. Flash beats GPT 5. Size isn’t everything.
Google’s model outperforms the expected champions. This isn’t as curious as it sounds, with Flash competing-with/outperforming 2.5 Pro in some of Google’s benchmarks. Gemini 3 Flash has consistently shown strong performance on natural language processing tasks that don’t get the same attention as coding or reasoning benchmarks.
That being said, the ~70% ceiling persists from v1. Another change in v2 is that all models took a 10 point hit that were in v1 (o1, o3, Claude 3.7 and 3.5), with the exception being the Gemini series (Flash and Pro 2.5), which did better relative to the other models tested with v1 at the time. This is most likely due to upgrades in the 2.5 family of models from preview to release; notably, the 3 Flash and 3 Pro are also preview versions which will mean testing again as soon as the general release is made.
But there remains a significant gap with open-source models with the GPT OSS series maxing out at 22.5%. Closed-source models are still significantly ahead. This aligns with the Irish-BLiMP paper’s findings on open-source models lagging behind on minority language tasks.
Noticeably, OpenAI’s GPT 5.2 Pro and a number of other models in the OpenAI series and Grok 4 are excluded, simply because I burned through my tech budget for the year in 3 days (whelp) 🥹
Key Feature Result Changes from V1 to V2
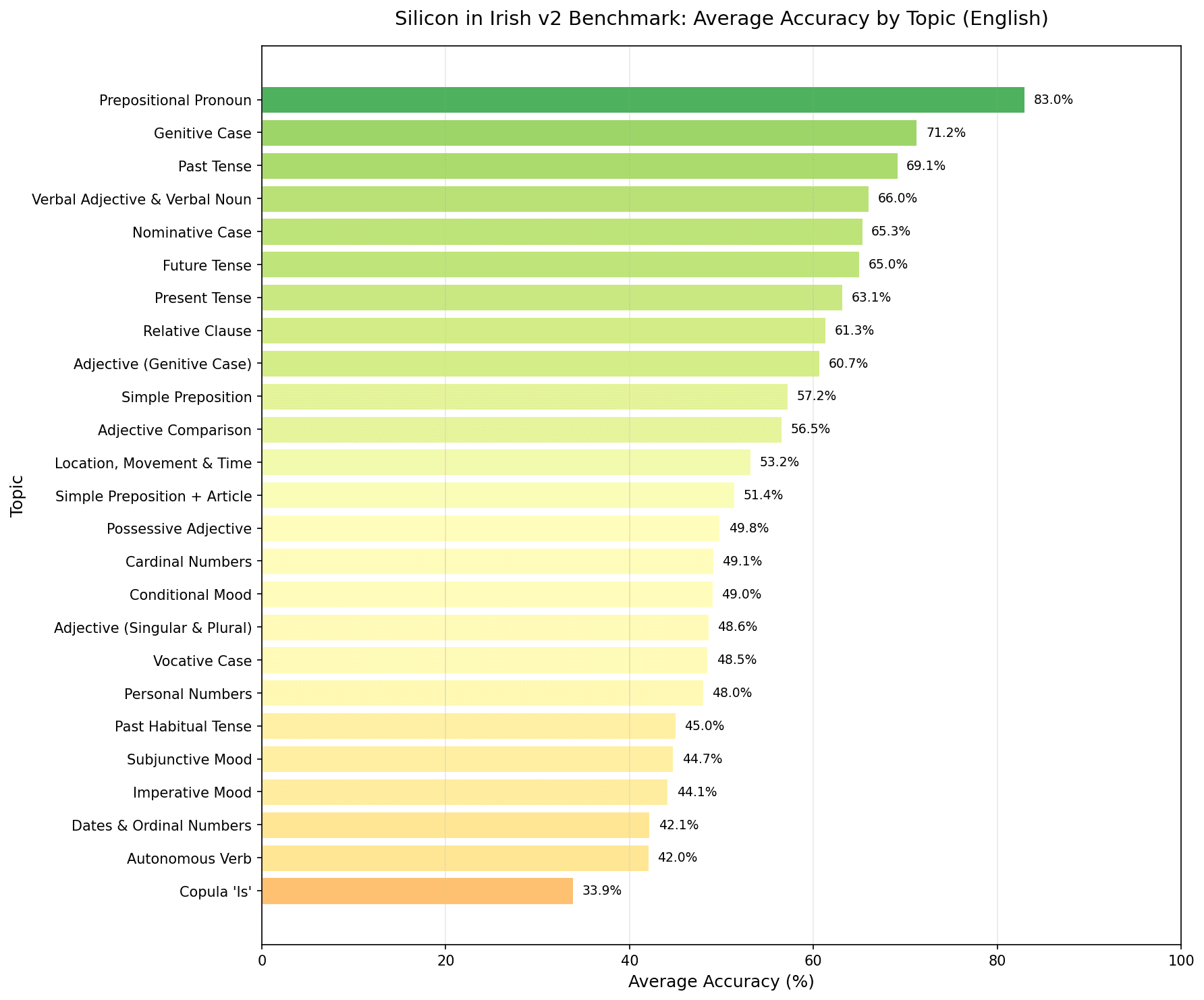
There are a number of stubborn features as we move away from features that are common in data
Accuracy varied greatly depending on the feature—hitting an average high of 83% for prepositional pronouns and a low of 33.9% for the copular forms.
Out of all the features that were updated, the Past Tense had the greatest change in results, improving by over 22 points:
- V1: 47.14%
- V2: 69.12%
A number of the tests in the V1 of the past tense were translation rather than fill-in-the-blanks or error correction, which allowed too much variability in the responses. This has been corrected using the hint approach.
Other Notable Shifts
- Copula (An Chopail Is): 59.79% → 33.86% — more nuanced tests exposed significant gaps.
- Prepositional Pronouns: remained strong at ~83%.
- New features (Subjunctive, Past Habitual): came in at 44-45% — as expected for rare forms.
What Hasn’t Changed: The Stubborn Features
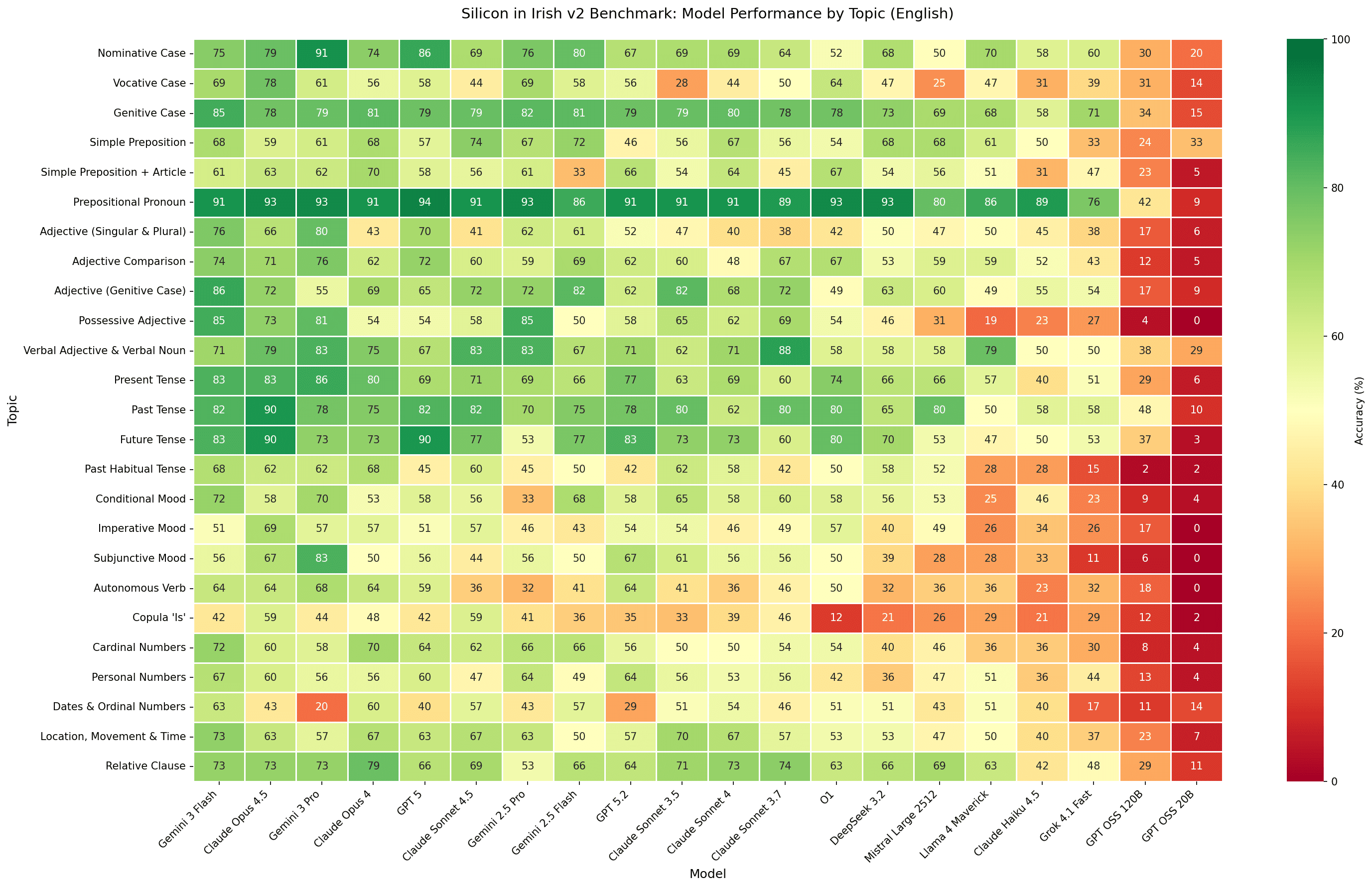
We can see how models performed in each topic ranging from 0% to 100% accuracy
Heat map of the accuracy of the models across features.
The heat map tells the story: Green areas (high accuracy) cluster around common, regular patterns. Red areas (low accuracy) are the stubborn features that all models struggle with.
Still Struggling
The copula (An Chopail Is) proved the hardest feature at just 33% accuracy—unsurprising given that the is/tá distinction has no English equivalent. The autonomous verb (An Briathar Saor) fared only slightly better at 42%, another construction with no true parallel in English. Dates and ordinal numbers (Na Dataí agus na hOrduimhreacha) came in at 42%, tripped up by their complex multi-word constructions. The imperative mood (An Modh Ordaitheach) reached 44%, with its subject-free forms and mutation rules causing consistent errors. Finally, the subjunctive (An Modh Foshuiteach) hit 44%. You may have seen it in “ go raibh maith agat ” which means “thank you” or literally “may you have good”.
These features share common characteristics:
- Uniquely Irish: no parallel in English or other major training languages.
- Rare in training data: less frequently encountered online.
- Multi-step transformations: require chaining several grammatical rules.
The copula is a perfect example. Knowing when to use “ is ” versus “ tá ” requires understanding a conceptual distinction that English simply doesn’t make. You can’t pattern-match your way to competence—you need to internalise the underlying logic.
Model Progression Over Time
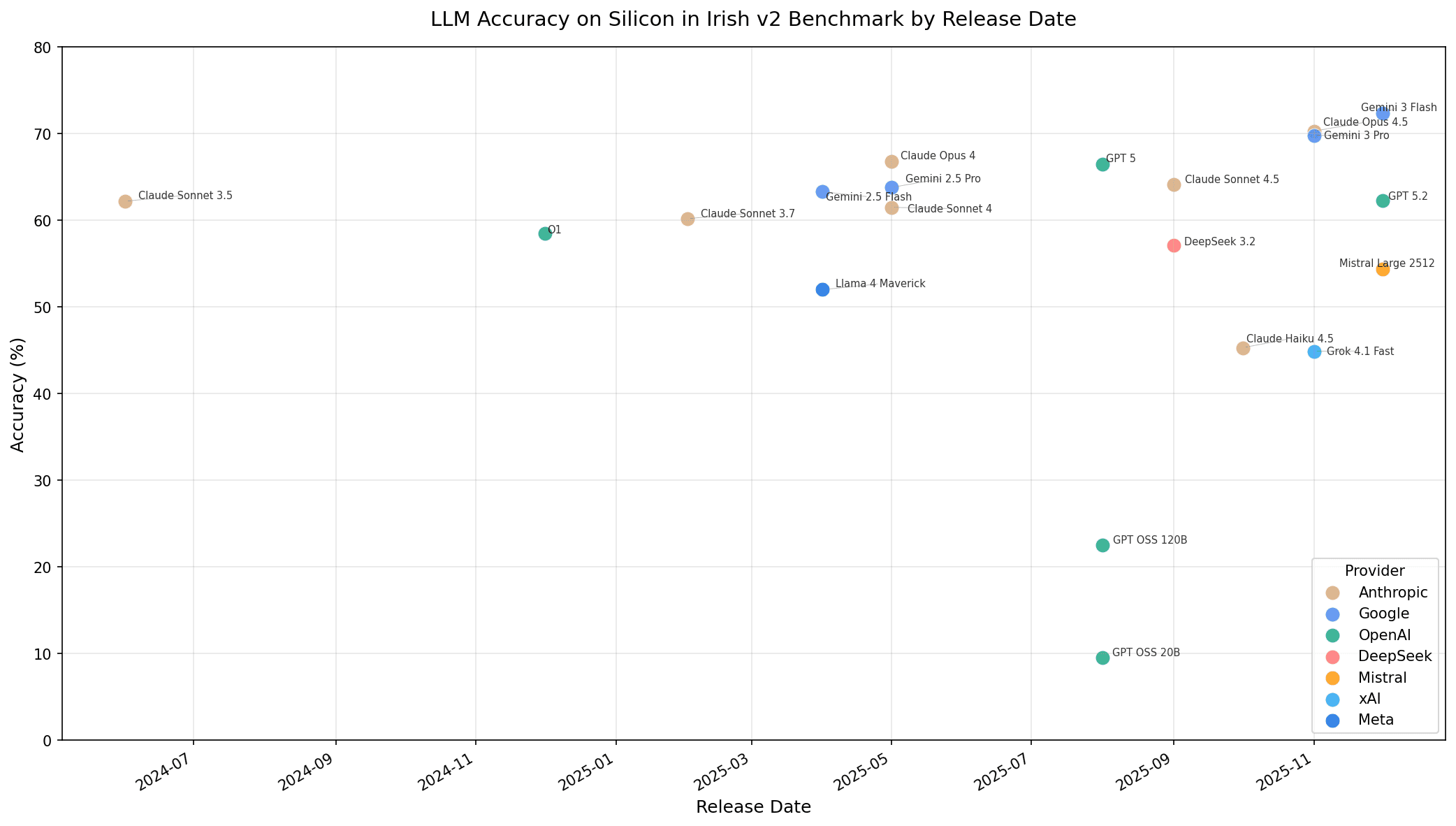
There is progress—however incremental—in the models on the benchmark across time
Models aren’t hockey-sticking up and to the right, but there is a subtle increment in performance over time.
Models are improving slowly. Plotting accuracy against release date (using AI Timeline for release dates) reveals a gradual upward trend rather than any breakthrough moment. Anthropic, Google and OpenAI cluster at the top, with Grok, DeepSeek and Mistral increasingly competitive, while other open-source models continue to lag significantly behind.
The Anthropic Family
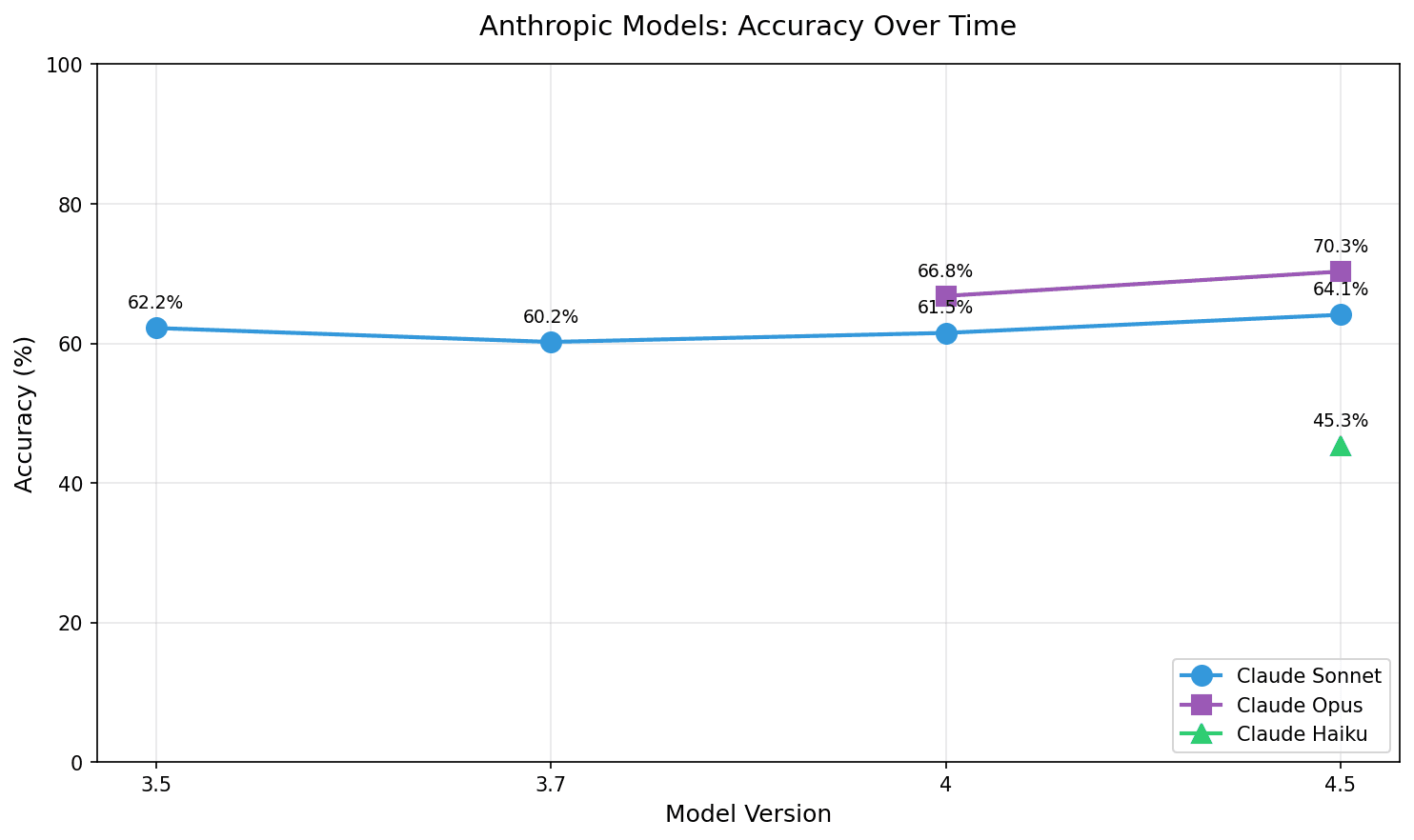
New models don't always mean better models
Claude gets back to where it began and then some.
The Anthropic timeline reveals something interesting: Claude 3.7 and 4 Sonnet were weaker at Irish than Claude 3.5 Sonnet.
This was also the case in v1. The 3.7 to 4.5 progression shows recovery and improvement, but that 3.7 dip is real. It suggests that whatever optimisations went into 3.7 came at the cost of Irish language competence.
The ~70% Barrier
Three independent studies now converge on the same finding and that convergence is remarkable. The Silicon in Irish v2 benchmark tests productive competence: can models generate correct Irish? It topped out at 72.4%. The Irish-BLiMP paper tests receptive competence: can models recognise correct Irish when presented with minimal pairs? It reached ~73.5%. Joseph McInerney’s work with Gaelchultúr’s assessment tests multiple-choice grammar testing, landing at ~73%. Despite completely different methodologies, generation versus discrimination versus selection, all three studies hit the same ~70% ceiling.
Looking Ahead to 2026
Building Better Tooling
I want to explore what comes when you give AI tools for Irish next. I’ve been exploring the infrastructure for the next phase:
- Searchable An Caighdeán Oifigiúil (Official Standard of Written Irish): the official Irish grammar standard, now indexed and searchable.
- Multiple dictionary sources: for vocabulary variation and examples.
Next Experiments
With the baseline established, we can now test enhanced approaches:
- Few-shot prompting: with explicit grammatical rules.
- Tool-augmented generation: let models search the Caighdeán Oifigiúil during generation.
- RAG approaches: with Irish grammar resources.
- V3 of the benchmark tied directly to the Caighdeán Oifigiúil which will complement the tool-augmentation.
The ~70% ceiling isn’t permanent. It’s a challenge.
V2 of this benchmark is more rigorous than v1. It confirms our earlier findings while exposing more refined details about where models struggle. The stubborn features (copula, autonomous verbs, subjunctive mood) indeed remain stubborn along with facets within them and other features. They require approaches beyond scaling.
The work continues.
To 2026, a year of new tools, more tests and better understanding.
Athbhliain faoi mhaise daoibh go léir!
Happy new year to all Caidéiseach ’s readers:]
If anyone is curious to talk more about this Irish-language tech or support these endeavours, reach out at caideiseach@gmail.com.
Thanks to Suhani Chawla for proofreading.